PufferLib 3.0: Better Reinforcement Learning at 4,000,000 Steps/Second
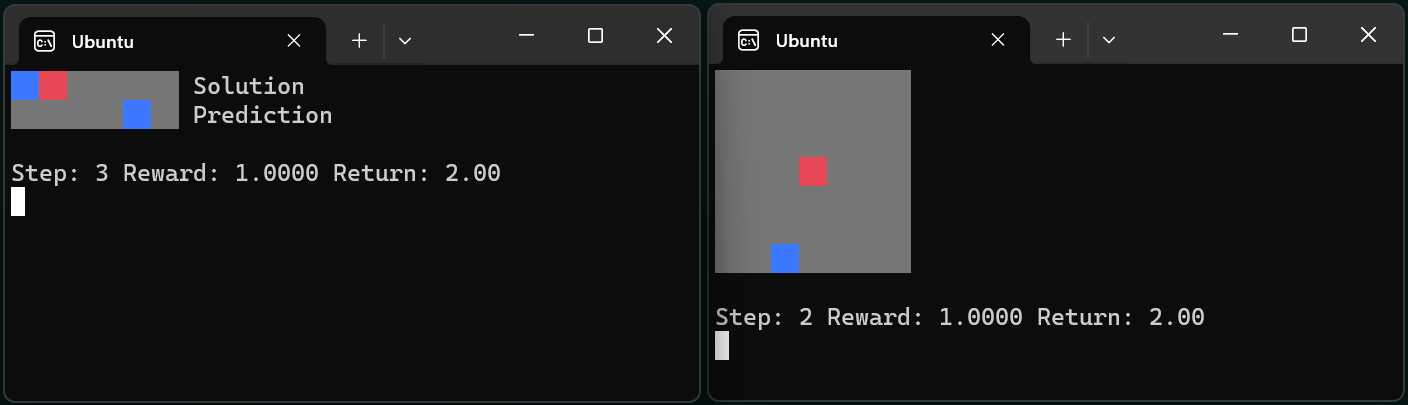
Sane and robust reinforcement learning is here! Our latest benchmarks train at up to 4M steps/second on a single RTX 5090. Here's a 30 second demo during which we solve Breakout from scratch:
The core training code is <1000 lines and we've spent a long time making it easy to follow. All our code is free and open source at puffer.ai, complete with documentation, a pip package, and docker images. Join discord for help or to get involved with development. We'll be posting a new article with details every day this week. For now, here are some highlights:
New Environments
We're adding 10 first-party environments to Ocean for a total of 22. Play them here online!
Hyperparameter Tuning that Works
Power up your RL with Protein, our new hyperparameter tuning algorithm! It's a heavily modified version of ImbueAI's CARBS that has set SOTA out-of-the-box for multiple clients. We've run tens of thousands of experiments with it across Ocean and third-party environments over the course of development. Here's Protein tuning a ludicrously hard maze environment:
Algorithmic Breakthroughs
Up until this release, we were just making existing methods faster. Not anymore! Our new trainer solves problems out-of-the-box that 2.0 couldn't solve in a 200 run sweep. The default set of hyperparameters solves most of the easier environments that used to require their own sweeps, too!
PufferEnv C API
It's easier than ever to build your own high-perf reinforcement learning environment. Our C API is an analog to Gymnasium with optimizations that propagate through Python. Native PufferEnvs simulate observations directly into shared memory batches with zero redundant copy operations. Two tutorial environments and a starter template are now available in our docs.
Hire Puffer
RL is hard. We make it easier. Hire us to get our eyes on your RL problem, assistance in fast simulation, prioritized feature development, and more. Priority service contracts start at 10k/mo, with larger contracts available for fixed deliverables. DM here or email jsuarez🐡puffer🐡ai.
Puffing Up PPO
Our day-to-day reinforcement learning work feels like a different field thanks to our new training algorithm. It often solves new environments out-of-the-box in seconds with default hyperparameters, and we're open-sourcing it with PufferLib 3.0. Star the project on GitHub to support our work!
A Hard Benchmark
We use arcade envs like Pong, Breakout, and Enduro for a lot of our early experiments. These are great because we can train a ~150k parameter MLP-LSTM at 2-4M steps/second (~10B steps per hour). We also use harder game environments like Neural MMO to test ~2-3M parameter networks at 500k-1M steps/second. In this release, we wanted a pure benchmark task with intuitive, easily scalable difficulty to complement our game environments. So we made Puffer Maze! We can generate any size maze we like and train on 11x11 crops of tiles at >1M steps/second with a 2M parameter model. If you're familiar with the literature, you'll know that RL isn't great at mazes, and most of the papers that use them are about hacking exploration bonuses. Our setting is a ludicrously sparse problem in which the agent only gets a reward at the very end.
Mordernizing the Optimizer
Our previous releases had a high-performance but algorithmically vanilla PPO implementation using Adam. This update uses Muon, which initially didn't seem to make much of a difference, but when we ran full sweeps, there was an immediate step-change in capabilities. The hyperparameters we found for Breakout not only solved the environment ~30% faster, but they also worked on nearly every other env in Ocean! Before this update, we would run a ~200 experiment hyperparameter sweep on each and every environment in order to get good baselines. We also swapped linear learning rate annealing for cosine annealing. This was a more minor detail: while having some form of annealing matters tremendously, we found that the method used doesn't matter much when swept alongside other hyperparameters. But cosine annealing produces more consistent learning curves during sweeps, which helps fit a model to hyperparameters.
Trajectory Segment Filtering
Apple's self-driving RL paper filtered out training data with uninformative advantage estimates. We've wanted to adopt this for a while, but the naive implementation breaks LSTMs. Our solution was to apply filtering to entire trajectory segments based on the sum of the advantage estimate over the entire segment of usually 64 observations. As an additional improvement, we apply prioritized experience replay instead of filtering over a fixed range. Neither of these techniques helps with every environment, but it can be a massive improvement if rewards are sparse. Prioritized replay is equal to uniform sampling with alpha=0 and beta_0=1, and we sweep both these coefficients, so we can easily see how much prioritized replay matters for any given environment.
Experience the Puffer Advantage
PPO was the algorithm OpenAI used to beat top pros at DoTA in 2019 and is probably the most widely used on-policy RL algorithm today. Half of what makes PPO good is clipping updates to avoid going too far off-policy. The other half is generalized advantage estimation, which scales rewards based on a fancy exponentially decaying average of n-step bootstrap estimates. In simpler terms: it determines how much a dollar today is worth vs. a dollar tomorrow.
The other really well-known on-policy algorithm is IMPALA. This one gets confused a lot, because it also introduced a ResNet-based architecture in the same paper. So when people say they are using IMPALA, half the time, they are just doing PPO with a ResNet and not actually using the algorithm. But when they are, the key to IMPALA is VTrace, which corrects off-policy updates. It essentially takes the clipping ratio used in PPO and uses it inside of the advantage function per-step, instead of just at the end.
Our original idea was to combine VTrace with trajectory segment filtering in PufferLib to keep around high-value data from epoch to epoch. That was way too off-policy and didn't work at all. But in the process, we spent a lot of time staring at the math... and realized GAE and VTrace are virtually identical! So we put them together and boom, Puffer Advantage! All the reference implementations we found for GAE and VTrace were pretty slow, so this release ships with a custom CUDA kernel. Puffer Advantage is equal to GAE when you set both clip coefficients to infinity and equal to VTrace with lambda=1, so our method is a strict generalization of both.
Stronger Hyperparameters with Protein
Power up your hyperparameter sweeps with Protein, PufferAI's new algorithm based on ImbueAI's CARBS. The original method stands for Cost AwaRe Bayesian Search because it models the Pareto frontier of cost (usually wall-clock time or steps) and score (your environment's performance metric). Our method modifies CARBS to:
Fix major edge cases. A big motivation for our new algorithm was that CARBS can be show to fail in very simple synthetic tests where any reasonable algorithm should succeed. For example, if CARBS has a confident but wrong model of the Pareto frontier, it degenerates to random sampling. It is very susceptible to noise in individual Pareto points (like lucky seeds) and in the Gaussian Processes it uses to model cost and score.
Fix data normalization. Gaussian processes expect normally distributed data. Performance decays quite rapidly if you feed in big numbers. CARBS is missing normalization in a couple of places, so you can have it work great on some environments and not at all on others.
Simplify the algorithm: CARBS is over 2,500 lines. The PufferLib sweep file is ~500. This is in keeping with our focus on simplicity in all things, and it makes reasoning about the code much easier.
CARBS
There's already a detailed manuscript on arXiv, but it's pretty dense, so read this section if you aren't already familiar with the algorithm. CARBS starts by defining the Pareto frontier as the subset of experiments where no other experiment is both better and faster, that is, higher score y and lower cost c.
In practice, CARBS starts out by running a few random hyperparameter sets to seed the Pareto front. From there, it picks new candidate hyperparameters with a normal sample around existing Pareto-optimal hyperparameters and downweights them based on distance.
These are just basic supervised learning problems. The first two map a vector of hyperparameters to the score and cost of the experiment. The last is a bit trickier: it maps the cost of each Pareto point to its score. The idea is that, if you tell CARBS how long you have to run an experiment, it should know how good the result can be. Now to actually select the points, CARBS uses these GPs to define an acquisition function:
This is run on each of the candidate hyperparameter vectors x that we got from P_search. If you ignore the second max for a moment and just use y_pf, then this is the difference between predicted score under GP_y and how well GP_pf thinks we can possibly do with any experiment that costs GPc(x). In practice, there's an extra term y_th to control exploration that we'll talk about soon. For now, just take the max of this function and you have your CARBS hyperparameter suggestion.
...Are bad for you?
This algorithm steamrolled ProcGen, so it's clearly pretty good. But the longer you look at it, the more problems you notice. First of all, P_search biases predictions to be close to existing Pareto points. Typically, you want longer and longer experiments over time as you become more confident in the results. So to counteract P_search keeping total timesteps (and therefore the run length) close to an existing point, there needs to be a counterbalance towards higher cost experiments. This is where y_th comes in. CARBS samples a random cost between the min and max pareto point and take a max with the existing sample y_pf. This punishes low-cost samples across the board
More problems come from explicitly modeling the Pareto frontier with y_pf. Suppose that all three Gaussian processes are perfect models. CARBS will then define GPy(x) - y_pf = 0. Since the acquisition function is 0 everywhere, you just end up with random sampling. This is true even if you don't actually have good experiments across the frontier. So even if CARBS fits a perfect log-linear scaling law to your problem, it won't actually try to run those more expensive experiments. And GP_pf is very sensitive, because it is only trained with the Pareto-optimal subset of hyperparameters. A lucky seed can throw it off, and the only remedy in CARBS is to periodically resample Pareto points, which requires rerunning old experiments 20% of the time by default. If you have even 5 Pareto points, you're going to have to wait 25 experiments on average before you maybe get an opportunity to correct one lucky seed.
Power up with Protein!
Our algorithm keeps GP_y and GP_c. Protein eliminates P_search and GP_pf, and it replaces the acquisition function with the following:
$$w(x) = \text{GP}_y(x) \cdot \left(1 - \left| \alpha U - \text{GP}_c(x) \right| \right), \quad U \sim \mathcal{U}(0, 1)$$
Alpha is fixed to 1.25 in our experiments. So this method picks a random cost between 0 and 1.25 and then scores candidate points x by penalizing their predicted score GP_y(x) by the predicted distance from that cost. We normalize scores between 0 and 1 and log costs between 0 and 1.25, so the predicted target cost can be up to ~77% (25% in log space) more expensive than the most expensive point. But we're still sampling around Pareto points only, so runs cannot become arbitrarily expensive without expanding the Pareto front.
Protein is a simpler algorithm than CARBS, but it is robust in ways that CARBS isn't. For example, Protein doesn't care that much if you get a lucky experiment because it doesn't rely on a model of the Pareto frontier. If Protein perfectly fits both GPs, 1/5 (alpha / (1 + alpha)) of experiments will target expanding the frontier to higher-cost regions. It also doesn't get stuck in low-cost regions that are difficult to model, which is a problem we saw with CARBS.
A few other optimizations we made that mattered quite a lot:
Instead of using only the final cost and score of an experiment, we downsample the training curve to 10 points and use them all as training data for both GPs.
CARBS seeds with several random trials. We instead use a single run with a reasonable set of defaults. Because this gives us 10 pareto points, we don't have to waste our first 10-20 experiments of every sweep.
We neatly normalize the search space of each hyperparameter between -1 and 1 to keep data in the domain expected by GPs.
We set the mean function for GPc to 1. This makes it overestimate how long unconfident samples will take during scoring.
The core logic for Protein is under 100 lines, so if you want to know every detail, read the code!
Speedrunning RL
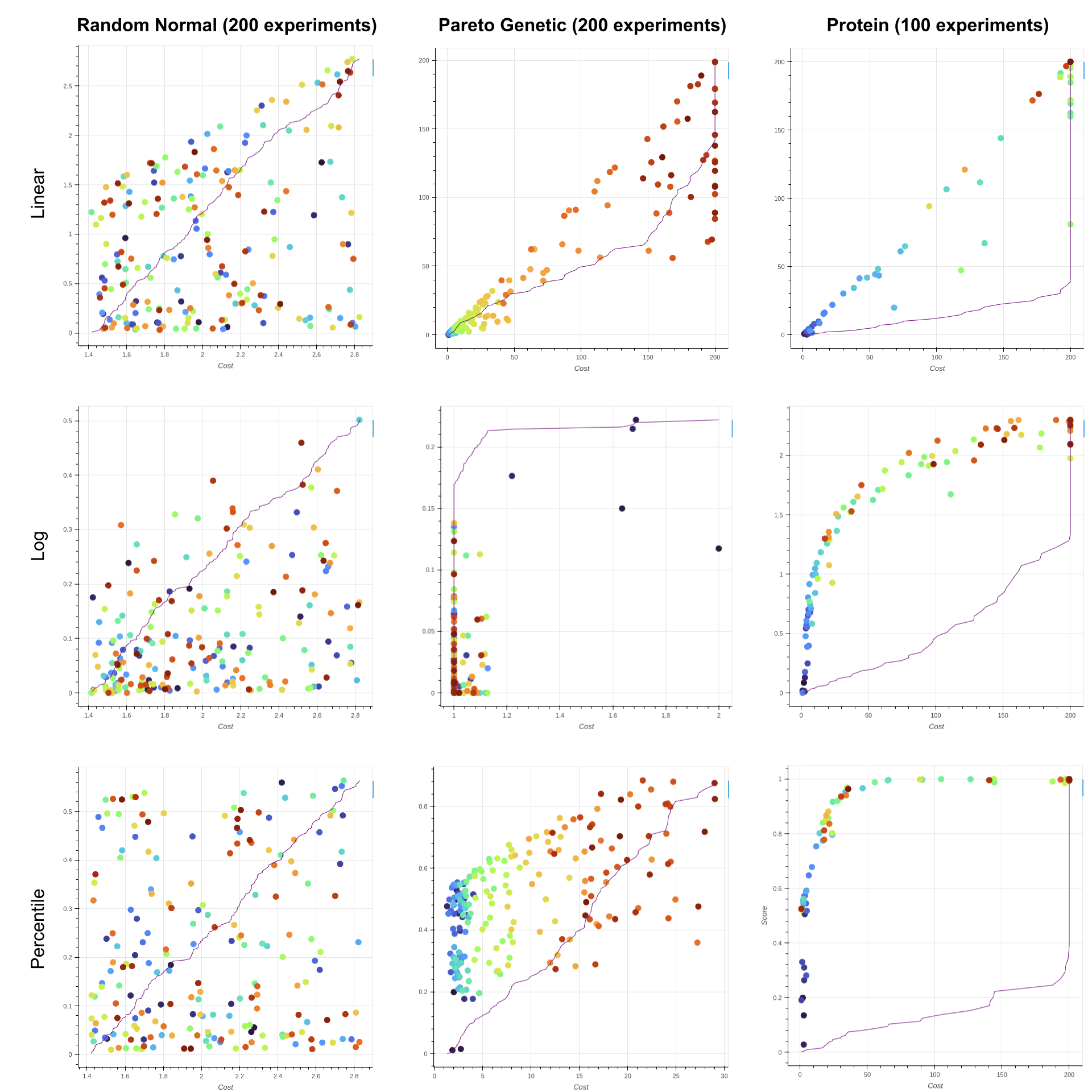
How fast can you solve Breakout with really good hyperparameters? We ran CARBS vs. random search, a pareto genetic algorithm (similar to Protein but without the GPs), and CARBS.
We also wrote some synthetic tasks to evaluate various methods. There is only one parameter to fit, but score is either a linear, logarithmic, or percentile function of cost. The costs for the log and percentile tasks have 20% noise to make it harder. We evaluated a random search that takes normally distributed samples from hyperparam default means, a pareto genetic algorithm that works similarly to Protein but without the gaussian processes, and Protein. The source for all of the methos is in pufferlib/sweeps.py. The synthetic benchmarks to reproduce our experiments are in tests. Here are the results:
Algorithm comparisons on synthetic tasks
Random sampling fails because it never evaluates high-cost parameters. Pareto genetic sometimes works if you give it enough runs, but it can get stuck if the Pareto points are too densely distributed (this caused it to fail the log task on this run). Protein solves them all, and in fewer experiments!
Catabolic Variations
We tried dozens of different scoring functions, normalization techniques, and objectives before settling on the current method. Here are some things that didn't work:
Fancy scoring normalization: It is common for hyperparameter sweep algorithms to apply some sort of scaling transformation to the target metric. But reinforcement learning score curves are quite varied! Breakout is scored from 0-864 points, where 550 isn't much different from 570, and 860-864 is just a matter of consistently hitting the last brick or two. Some environments use win-rate as a metric, so 0.999 is 10x better than 0.99. Other environments like Enduro are endless and have virtually linear learning curves with ever-improving scores. In our synthetic tasks, it was quite easy to improve one shape of curve at the expense of the others, but simply normalizing the min and max scores from 0 to 1 was the best overall.
Anything relying on a difference between GPs: We found that the trained GPs are at most directionally correct and quite noisy, with meaningless learned variances. This was the main reason we scrapped GP_pf.
Anything relying on specific Pareto points: One early variant attempted to maximize the distance between the next experiment and existing pareto points in cost space. It could be shown to converge to binary search under perfect GPs, which is a really nice property to have. Unfortunately, relying on an individual Pareto point once again creates instability to lucky seeds. The method worked great on initial synthetic tests but collapsed when we introduced noisy score estimates.
Maximizing information gain: Another early idea was to reward Protein based on the improvement made per compute spent. We could only make this work with a known learning curve shape, because the meaning of relative changes in score varies wildly per environment. This is still one of my favorite ideas, but it would require substantial rethinking and perhaps online curvature estimation.
PufferLib 2.0: Reinforcement Learning at 1,000,000 Steps/Second
Welcome to a new age of reinforcement learning. This is our biggest release ever. 11 new environments totaling ~20,000 lines of pure C. They all run >1M steps/second (sps) on a single CPU core, and you can train at 300k-1.2M sps on a single GPU, depending on the environment and policy. That means you can run centuries of simulations per GPU per day. Academic labs with a handful of GPUs now effectively have thousands. It's all free and open source under the MIT license -- star the repo to support the project!
About half of the new environment code was written by open-source contributors. Thank you all for making this possible. A full list is available on the project page.
Puffer Ocean: Our Environments
You can play these yourself or watch our pretrained agents running live in your browser. Each of our new environments are written in C as a single .h file. There is nothing fancy here, and the only dependency is raylib for rendering. Anyone who has taken a single systems course can understand and contribute to the code. The main techniques we use for performance are:
No dynamic memory allocations. Everything is allocated during initialization.
No observation copies. Environments write observations directly to the buffers used for training.
Aggressive caching. The most extreme example of this is in the MOBA, where we store 250MB of pathing data.
We bind environments to Python via a short Cython intermediary layer. Each environment also has a Python stub defining observation and action spaces and wrapping the Cython step/reset/close functions. This means that environment devs more comfortable in Python can prototype there before porting to Cython or C for performance. Cython is plenty fast, but C makes it easy to compile for web. We load PyTorch models with a ~500 line puffernet.h to demo trained agents in your browser.
Native PufferEnv API + Vectorization
Even with a 1M sps environment, you still spend 15 minutes on simulation per billion steps trained. With PufferLib, it's more like 10 seconds because of asynchronous on-policy sampling. When your policy is computing actions for one batch of environments, another is stepping in the background. By the time your forward pass is done, new data is ready with 0 downtime. This is a fancy implementation of EnvPool with some extra tricks. It's compatible with everything, not just our native envs, but that's where you'll see the biggest benefit. Details are in the PufferLib whitepaper on arXiv.
To achieve this level of performance, we introduce a new PufferEnv API for native environments. It's less than 100 lines and allows new environments to take full advantage of the rest of PufferLib's optimizations. Native environments skip the Python loop over agents as well as several redundant copy operations. Our multiprocessing implementation checks if you are using a native environment and, if you are, it passes your constructor a pointer into shared memory. Each C environment then writes observations directly into that buffer, so they are immediately available on the main process.
In case you're worried about compatibility, don't be. Everything can still be run with Gymnasium/PettingZoo. We just use a VecEnv style API by default. Async mode is a superset of Gymnasium, so you can start off synchronous and implement async with a few small changes to your training code. And even if you don't do any of that, you will still be able to train an order of magnitude faster than with more standard environments.
Reinforcement Learning Quickstart Guide
So you want to learn reinforcement learning? It's a hard mountain to climb, but I'm going to be giving you some of the best tricks and insights from my playbook. Star PufferLib on GitHub if you learn something useful. It's the library I'm building to make RL fast and sane.
What is RL?
(Deep) reinforcement learning is a branch of ML focused on learning through interaction. You are training an agent or policy. Both of these just mean neural network. The world, game, or sim the agent is interacting with is called the environment, which is in a particular state at any point in time. The agent makes an observation of the state at each timestep. That's the data it sees and can use to make decisions. In some environments, this is simply the full state, in which case we say the environment is fully observed. Otherwise, it is partially observed. In math heavy RL lit, you will see these described by Markov Decision Processes (MDP) and Partially Observable MDPs (POMDP). Consider this nomenclature optional. The agent makes an action based on the observation, which is then used to step the environment forward in time. The environment will return a reward based on what happens in the environment. This can be 0 and often is, but it might be 0.5 if an agent scores a point and -1 is the agent dies, for example.
Fundamentals
There are a few different common classes of algorithms, as well as some stuff masquerading as RL that really isn't. I'd rather eat broken glass than read academic papers all day, so I'll keep the background material light.
On-policy: You learn a function that maps observations to actions. Read Karpathy's blog post on policy gradients, then skip right to the PPO paper. You might need to refer to the Generalized Advantage Estimation paper for context.
Off-policy: You learn a function that maps (observation, action) to some value that tells you how good that action is. The agent then acts either by selecting the highest-value action, or sometimes by sampling. You should absolutely read DQN as one of the first fundamental papers in this area. Then, skip right to Rainbow because it summarizes and cites most of the intermediate improvements anyways. Nowadays, Soft Actor Critic is the most widely used off-policy algorithm. (Edit: Yes, I am aware that off-policy is typically defined as training on data that doesn't come from the policy. Stay tuned for a follow-up on why this distinction is largely irrelevant and misleading)
Researchers made a big deal about on-policy vs. off-policy in the mid-late 2010s. It really doesn't matter that much. There have even been theoretical results showing some equivalences. Kind of expected. On-policy maps observations to actions but usually also predicts a value function. Off-policy predicts a sort of action-conditioned value function. The big difference is that off-policy algorithms are almost always trained with some sort of experience replay, meaning that the algorithm collects and samples training data from a big buffer. In contrast, on-policy methods usually use data as soon as it is collected... but the batch sizes can get pretty huge, so again, the differences are exaggerated.
Model based: is poorly named. In this context, "model" refers to the environment. Your agent is trained to directly predict future observations. You can use this as an auxiliary loss or even use the learned world model to simulate new training data. Model-based training is intuitively appealing and has shown some impressive results, but some of the recent lit is a bit dodgy. Most of RL is model free. I suggest the original World Models paper by David Ha & Schmidhuber.
Offline RL: is not RL. It's supervised learning on a fixed set of observations, actions, and rewards usually collected from humans or by an expert policy. This is similar to imitation learning or behavioral cloning, but with the addition of a reward signal. Either way, it is missing the key element of learning through interaction, since the policy does not have any control over its data collection.
Multiagent RL: Is the same as single-agent RL except that some of the environments and tools are jank. The most common approach is to use the same policy for all agents, applied independently. This is as if you had N single-agent environments instead of one N-agent environment. See? No different from single-agent. You can also compute actions jointly just by concatenating all the observations for a single environment together. Sometimes researchers come up with separate algorithm names to describe these techniques, like IPPO and MAPPO... but this is really all there is to it. There are also some dedicated multiagent algorithms, but having worked extensively in multiagent RL, these are pretty mixed.
Perspective
Learn which areas of research to pay attention to and which you can ignore. The large-scale industry papers are great for developing this intuition. If I had to pick just one, it's OpenAI Five. PPO with simple historical self-play solves DoTA. There's a lot more in that paper, too. The core architecture is a 1-layer 4096 dim LSTM. The other papers are Alphastar, Learning Dexterity, Emergent Tool Use, and Capture the Flag in roughly that order. Don't forget about the whole AlphaGo line from DeepMind!
So why is this relevant? There's some important missing context here... RL is very sensitive to hyperparameters, and many of the common benchmarks are slow. Couple this with starving academic budgets and you inevitably get a lot of bad science. Algorithm A does 20% better than algorithm B, but hyperparameters alone make a difference of 3x. So why even bother developing fancy new algorithms if you can't test them properly? Well, that's how you get published. And a lot of the people developing faster envs were treated so badly by academia that they took their ball and went home (hint, that's why I just write blogs now!).
So how do you know what lines of work are promising? Look for papers with comprehensive experiments and ablations. Especially the ones that do this on one core idea. I particularly like the OpenAI blog post how AI training scales and the paper scaling laws for single-agent reinforcement learning. Personally, I think the most promising thing right now is to just rerun old work with more experiments on faster environments. We're developing tons of these at Puffer, so you can run hundreds of experiments per GPU per day. If that sounds boring, learn to be excited by the result rather than the method. The goal is to understand, and science is just one tool for doing so.
I also avoid work that advances research now at the price of making it slower in the future. Anything introducing slow environments or expensive training had better have a very good reason for it. On the contrary, anything that improves the pace of research is shortlisted. DreamerV3 caught my eye because it worked with one set of hyperparameters... but that was before blowing 10,000 A100 hours on ablation studies. You won't always be right!
When I'm assessing a new area of work, I always look for wrong fundamental assumptions. For example, a lot of work in curiosity or exploration don't reasonably define those terms. Several papers in this area abuse human intuition to propose environments that look easy, but are actually hard or impossible to learn tabula-rasa, or from a blank slate. That doesn't mean I won't consider any of the ideas from these papers... but I'm going to assume that the results don't generalize until a mountain of evidence proves otherwise.
Things I use a lot
PPO: This is my go-to algorithm. It's simple and solved DoTA. Actually, it's simpler than most people appreciate. The way to think about PPO is vanilla policy gradients + GAE. That's just fancy exponential reward discounting with a value function baseline. Then, it adds policy clipping. This just means each weight can't change too much on any single update. Clipping lets PPO use the same batch of observations for multiple gradient updates. But if your environment is really fast, there's not much reason to do that, since new data is free. So it's just a simple and effective sample efficiency hack. Read Costa's 37 PPO details blog if you really want to understand the algorithm.
Hyperparameter Intuition: I'll cover these for PPO, but several are common across many algorithms. Learning rate, gamma, and lambda are the most important. You always sweep learning rate. Gamma and lambda are GAE parameters that relate to the effective horizon of your task. I like to think about the effective horizon of my task. For instance, in Pong, you don't need to look ahead more than a couple of seconds. If the framerate is 15, then there are 30 frames in 2 seconds, so I might try 1 - 1/30 = 0.97 as a starting point. Lambda is usually set a bit below gamma, so I would try 0.95. This should at least give you a decent starting point for an automated sweep. I leave clipping parameters at 0.1 or 0.2. Tuning these lower will cause aggressive "on rails" runs that learn well for a while before diverging. Batch size, minibatch size, and number of environments should be set based on hardware. For my fast environments with small networks, batch size 4096 is hardware efficient, so I use 4096 environments. Then I multiply by 128 to get the batch size. The reason for this is to allow GAE to compute discounted returns over 128-length trajectory segments. Decrease this if your environment has very short horizons or increase it for longer ones. I set minibatch size to be a quarter of batch size by default, but I also set this one based on GPU memory. Update epochs is 1 for fast environments or 3-4 for slow environments. You can go higher, but then you have to also worry about KL targets.
CARBS: A really good hyperparameter tuning algorithm from ImbueAI. We have bindings in PufferLib, and it is way better than standard random or bayes. We're still learning how best to configure this, but even if you do it wrong, it's still usually pretty good. Don't sweep clip coefficients like I mentioned above, otherwise you get some pretty nutty runs.
Common Architectures: I use an LSTM by default because it's fast and PufferLib makes adding one trivial. This replaces the main hidden layer, so networks can be as simple as fc-relu-lstm-fc-atn/val with 128-512 hidden dim. For 2d data, I will usually use a stack of 2-3 convolution layers with relus as an encoder. Avoid redundant fully connected layers when combining data from multiple sources, such as flat and 2d data. Deeper networks are not always better in RL, and they can sometimes be much harder to train. Also, know that RL tends to be more data hungry than other areas of AI, so you are often better off running more samples on a smaller network. That presumes your problem has a fast simulator. Feel free to experiment more here if you don't. The resnet architecture from the Impala paper is a decent slower one.
Normalize your data: Observations should be divided into discrete and continuous. One-hot or embed discrete data. Divide continuous data by its maximum value per channel. Do not do this using mean stats. Just say "max health is 100 so I will divide by 100" etc. Do the same for rewards.
Designing Rewards: These days, I just pick 3-5 things in the environment that are relevant to performance. For my MOBA, I did agent dying, getting xp, and taking a tower. I come up with rough guesses of the coefficients in the range of -5 to 5 (-0.5 to 0.5 for more common rewards). Then, I add the reward components to a hyperparameter sweep and tune them automatically. Be careful with continuous rewards. If you want an agent to go to a target, 1 for getting closer and -1 for getting farther is way better than just negative distance to target. The reason is that if the agent gets 0.01 closer, it might have a reward of -0.95 one step and -0.94 the next. Not much of a magnitude change to differentiate.
Whitebox software: Try not to over-modularize RL. CleanRL provides single-file training implementations, and if you talk to any researchers, you'll quickly find that it's the best thing since sliced bread. Anything and everything can go wrong in RL, and you don't want to be digging through several layers of abstraction searching for the issue. I can't tell you how many times I've seen environments break because someone forgot they were using some wrapper that no longer made sense. Or just an environment was passing data in a weird way. Seriously, just keep it simple. A high level API isn't going to save you. Assume anything you build will break, and you or someone else will have to read the source for it.
General engineering: Lots of AI researchers work out of notebooks. That doesn't fly in RL. In addition to the whole normal ML stack, RL requires you to deal with high-performance distributed simulation. The biggest innovations in PufferLib required me to get my hands dirty with asynchronous multiprocessing. Once that was done, I was able to 100x the standard training speed by writing envs from scratch in C. If you're coming from high level dev, it's much easier than you'd think. I wrote Python for 10 years. Within just a few weeks, I was as productive in C as in Python, and now I'm actually more productive. How is that possible? Well, I don't have to think about fancy performance optimization tricks. I just write the braindead loops and it's fast, done. You wouldn't believe some of the hoops I had to jump through during my PhD to get Neural MMO to run fast enough in Python.
Write better code: This one is more personal, but I'm irrationally obsessive about code quality. In order to get better, bad code has to cause you severe mental distress. I've gone through several phases here, some of which involved me writing a lot of bad code. One thing I want to emphasize: good engineers don't use every design pattern in the book. If you learned Java, unlearn it. No abstraction is zero-cost, and first year CS students should be able to read almost all of your code. I've hit a kind of zen state where dev is pretty easy, and I'd like to think I make it easier for new contributors too.
Contribute to PufferLib
I'm not here to sell you courses. I wrote this mostly so new contributors would have a place to start. Many came in with zero RL experience. I spend a lot of time going through PRs and helping fill in knowledge gaps on stream or in voice chat. This all happens through the Discord. Folks usually start off by contributing to environments and then move into the science side as they get more comfortable. Major contributors even get hardware access for running experiments!
PufferLib 1.0: Now Stable
Our first stable release. This update doesn't have any fancy new features, but it fixes a ton of common pain points. Here's 30 minutes of fast and simple reinforcement learning demos. As of this update, we now offer priority service packages for companies.
The Puffer Stack
Thank you for 325 stars on PufferLib! As promised, this is a complete teardown of our stack including hardware, containerization, dependency management, and more.
8 RTX 4090s, 1 Titan V, 200 cores, and 1056 GB of RAM
Hardware
We have 8 Maingear desktops (we call them puffer boxes) with one 24GB RTX 4090 each. The CPUs each have 24 cores. One has an i9 13900k. Five have i9 14900k’s. Two have i9 14900ks’s. Each machine has 128 GB DDR4 RAM. There is also a login/testing machine with a Titan V, 32GB of RAM, and an 8-core i7 9700k. The main machines retail around $4000 each. The 4090s are overkill for most jobs, but we wanted to have the option to scale up models and experiment with new architectures.
All machines are connected to gigabit ethernet. Power is supplied with a standard 20-amp outlet per 2 machines. Machines sit on a utility rack that is grated to allow air intake from below. Exhaust is backwards, towards the wall, which has about 2 feet of free space. A small industrial fan is angled so as to push hot air away from the back wall. The room is maintained at 80F.
Issues & Gotchas: We have had some stability issues that I am 95% certain are caused by faulty 14th gen intel chips. The motherboards are running Intel’s suggested power settings, but a couple of the machines still get occasional crashes. Unrelatedly, the chip architecture is 8 p-cores and 16 e-cores. To get good performance out of these chips, asynchronous environment sampling is a must. We also discovered that these machines would not boot properly from a hard reset when not connected to a monitor. We bought some dummy HDMI plugs to trick the machines into booting headless.
Installation & Containerization
Machines are installed with a minimal build of Debian 12. The PufferTank repository on Github contains our setup script. For now, this is done manually on each machine. It installs NVIDIA drivers, utilities like git and vim, docker, and Tailscale. We rely on Tailscale for credentialing users and general administration. There is no Slurm, shared file system, or other such layers. Users are assigned one or multiple machines to use for development and experiments.
Each machine contains a build of PufferTank. Images for PufferTank are available from pufferai on docker hub or through the PufferTank github repository. PufferTank is a 3-stage docker build. There is a base layer that installs (currently) Pytorch 3.4 and Python 3.11, as well as basic utilities. A second layer installs dependencies for tricky RL environments like Nethack and DM Lab. The final layer is a quick build that clones PufferLib, sets a few environment flags, adds a bit of configuration to bash, and also installs Neovim. The idea is that the first layer doesn’t change often, the second layer changes whenever we add new envs, and the third layer is rebuilt quite often.
Puffer hardware users are booted into PufferTank on login. They can also spin up their own container in seconds, in cases where a fresh install is needed or a machine is being shared.
PufferLib dependency management
PufferLib provides a pip package with a long list of optionals, one per environment. There is a common extra that will install all of the environments (or at least the ones that play nice together). This is the default in PufferTank. We set sane default versions of Gym/Gymnasium/PettingZoo for maximum compatibility. Some extras outside of common may override these. PufferLib provides short bindings for each environment, but no registry. We wrap environments in PufferLib’s emulation layer for compatibility, which is a 1-line change. For Gym environments, we apply a Gymnasium compatibility layer. For old PettingZoo environments still based on the Gym API, we apply a similar compatibility layer. For most environments, we apply an episode postprocessing wrapper that cuts down on data transfer during multiprocessing. Some environments have additional wrappers to make them render nicely or fix various quirks. But in general, we keep the stack as thin and as simple as possible. We considered folding the postprocessing wrapper into the vectorization module for this purpose, but enough envs return nonstandard data that this is not worth doing at the present.
Summary
This is a very simple cluster, but we get a lot of mileage out of it. Most folks don’t realize how fast high-end desktop processors are compared to 10x more expensive server CPUs. One puffer box was 3x faster than the CPU in an 8x A100 server we previously had access to. With discounts, an 8x A100 box is still going to be $100k+. Our entire setup is around $35k. This was a lot of money for me to spend, but it is currently powering 4 different RL projects. And with the prices outside something like Vast, the buy price is only 2-4 months of rental pricing.
One of the worst things you can do is to adopt heavy tools and then use them wrong. No shared file system, Slurm, etc. means less stuff to manage and less stuff in onboarding. We can get new users onto a machine with their own dev environment that exactly matches their local one in 5 minutes.
PufferLib 0.7: Puffing Up Performance with Shared Memory
This update doubles training throughput for most environments with no tradeoffs. We have tested Pokemon Red training at over 6000 steps/second on a single desktop, up from around 3000. CleanRL trains Atari 65% faster just by switching to PufferLib's vectorization, without even enabling our extra async features. The approach is a combination of shared memory, PyTorch code optimizations, dependency upgrades, and model compilation.
Sharing Memory with Vectorized Environments
In PufferLib 0.5, we discovered that the standard Python multiprocessing Queue implementation is 3-10x slower than using Pipes and replaced it accordingly. In this update, we discovered that sending environment data through multiprocessing.Array instead of through Pipe yields an additional ~20% performance improvement. This is the exact code we use:
shared_mem = [
Array('d', agents_per_worker*(3+observation_size))
for _ in range(num_workers)
]
Each array has enough memory for all of the observations, rewards, terminals, and truncation signals from the environments on one worker. Only the actions and infos are still communicated via pipes. Since infos can store arbitrary data and are the simplest way to aggregate logs from the environment, we have left this as is. The multiprocessing.Array is also shared with a Numpy array, making it simple to update:
This function is called only once per worker at the start of training, and the data arrays can be updated in place to update the corresponding shared storage. These slices are views, meaning that they are fast to update without first having to aggregate all the data from a worker into a local array.
Slow indexing is a `known issue `_ in PyTorch. PufferLib’s customized CleanRL PPO implementation has to do a lot of indexing because it uses an EnvPool-like interface that does synchronous policy updates but asynchronous environment simulation. After profiling, we found that indexing and subsequent copying were taking up 80% of inference and 50% of training. The fix for this was to just use Numpy. Calling np.asarray(tensor) creates a shared memory view in which updating the numpy array also updates the tensor, but it allows you to use 10x faster Numpy indexing to do it. It only works on CPU, but we were already offloading most of the rollout data to CPU anyway to enable large-batch training, and this only adds a few copies per epoch.
Dependency Upgrades & torch.compile
We’ve updated PufferTank to Python 3.11 and PyTorch 2.1 with Cuda 12.1. This enables us to use torch.compile, which you can enable in the demo with the —train.compile flag. This gave us another 20% model throughput in our testing. Python 3.11 also contains a number of performance improvements. The one issue is that 3.11 specifically breaks a few important environments. We’ve included a build of NetHack that works with 3.11, and Neural MMO will be updated soon. If you are having trouble with any specific environment, let us know on the Discord.
Attribution
Thanks to ThatGuy in the Pokemon Red RL Discord for profiling and optimizing clean_pufferl and Bet Adsorption for assistance
Thanks to Aleksei Petrenko, the creator of Sample Factory, for useful discussions and pointers to optimizations in the Sample Factory code base. Aleksei also has a useful pip package, faster-fifo, that fixes the horrible performance of Python’s native multiprocessing.Queue. It’s much simpler than raw Pipes and nearly as fast.
PufferLib 0.6: 🐡🌊 An Ocean of Environments for Learning Pufferfish
Ocean is a small suite of environments that train from scratch in 30 seconds and render in a terminal. Each environment is a sanity check for a common implementation bug. Use Ocean as a quick verification test whenever you make small code changes.
Ocean test environments
Memory: The agent is shown one binary token at a time and must recite them back after a pause. Do not make the sequence too long or you start testing credit assignment.
Stochasticity: The agent is rewarded for learning a particular nondeterministic action distribution. Do not use an architecture with memory or the agent can solve the task without stochasticity.
Exploration: The agent is rewarded for guessing a specific binary sequence. Do not tune your entropy coefficients higher than you would use in your actual environments, since that is the point of the test.
Bandit: The agent is rewarded for solving a multiarmed bandit problem. This environment is included for historical importance. Any reasonable implementation should solve the default setting.
Squared: The agent is rewarded for moving to targets that spawn around the edges of a square. There are settings to test memory, exploration, and stochasticity separately or jointly to help you prod at deeper issues with your implementation.
This project is heavily inspired by BSuite, a DeepMind project with similar if more benchmarky goals. BSuite was a bit too heavy for my liking and didn’t fit the niche of a quick and portable verification suite.
I had a few issues designing these. The memory task is apparently a standard RNN copying task (I would be surprised if it weren’t). But it’s a bit different in an RL context because you still have to learn credit assignment. I don’t think there is a way to fully isolate learning only memory outside of a simple 1-step problem. Try increasing the memory sequence length or delay and you will quickly find that the problem gets harder to learn.
The exploration environment is the only one that just worked. You can increase the password length and the problem gets harder to learn at about the rate you would expect. It’s just a guess and check, so once you happen to get the password right once, the goal is to learn from that single instance as much as possible. Any prioritized replay would trivialize the problem.
The stochastic environment took the longest. Initially, I was looking for one where the optimal policy was still stochastic and nontrivial even if the agent had memory. I could not figure out how to make one of these, and Twitter seems to think it’s impossible. They’re probably right, though you might be able to alter the setup conditions a bit, still test for the same thing, and have something that works better. For now, this is a quick and consistent test.
I wrote the bandit environment earlier in the project, and it seems kind of useful, so I left it in the release. Probably a good idea to have at least some version of a problem this historically important easily accessible in PufferLib.
I wrote Squared over the summer. I’m rather fond of it as a test environment, since it is fairly scalable. You spawn at the center of a square and targets spawn around the outside. You get a reward the first time you hit each target and are teleported to the center whenever you hit a target. This means that the optimal policy is stochastic: you place equal probability on moving towards each target and then deterministically move towards the target you have selected. It’s interesting because the optimal policy is stochastic in some states and deterministic in others. You can also turn the problem into a memory test by using a recurrent network. In any event, it’s similar to the bandit problem in that it combines elements of the simpler tests, but it’s a bit more tunable and interpretable.
Let me know if you have other ideas for useful test environments. Lately, I’ve landed on either very simple or very complex environments as being the most useful for research. Many of the tasks in the middle (looking at you Atari) are too slow to be useful as quick tests and too simple to test interesting ideas.
PufferLib 0.5: A Bigger EnvPool for Growing Puffers
This is what reinforcement learning does to your CPU utilization:
You wouldn’t pack a box this way, right?
With PufferLib 0.5, we are releasing a Python implementation of EnvPool to solve this problem. TL;DR: ~20% performance improvement across most workloads, up to 2x for complex environments, and native multiagent support.
If you just want the enhancements, you can pip install -U pufferlib. But if you’d like to see a bit behind the curtain, read on!
The Simulation Crisis
You want to do some RL research, so you install Atari. Say it runs at 1000 steps/second on 1 core and 5000 steps/second on 6 cores. Now, you decide you want to work on a more interesting environment and happen upon Neural MMO, a brilliant project that must have been developed by a truly fantastic team. It runs at 1500 steps/second – faster than Atari! So you scale it up to 6 cores and it runs at … 1800 steps per second. What gives?
The problem is that environments simulated on different cores do not run at the same speed. Even if they did, many modern CPUs have cores that run at different speeds. Parallelization overhead is mostly the sum of:
Launching/synchronization overhead. This is roughly 0.1 ms per process and is linear in the number of processes. At ~100 steps per second, you can ignore it. At >10,000 steps/second, it is the main limiting factor.
Environment variance. This is defined by the ratio mu/std of the environment simulation time and scales with the square root of the number of processes. For 24 processes, 10% std is 20% overhead and 100% std is 300% overhead.
Different core speeds. Many modern CPUs, especially Intel desktop series processors, feature additional cores that are ~20% slower than the main cores.
Model latency. This is the time taken to transfer observations to GPU, run the model, and transfer actions to CPU. It is not technically part of multiprocesssing overhead, but naive implementations will leave CPUs idle during model inference.
As a rule of thumb, simple RL environments have < 10% variance because the code is always simulating roughly the same thing. Complex environments, especially ones with variable numbers of agents, can have > 100% variance because different code runs depending on the current state. On the other hand, if your environment has 100 agents, you are effectively running 100x fewer simulations for the same data, so launching/synchronization overhead is lower.
The Solution
Run multiple environments per process if you have > ~2000 sps environment with variance < ~10%. This will reduce the impact of launching/synchronization overhead and also reduces variance because you are summing over samples. In PufferLib, we typically enable this only for environments > ~5000 sps because of interactions with the optimizations below.
Simulate multiple buffers of environments so that one buffer is running while your model is processing observations from the other. This technique was introduced by https://github.com/alex-petrenko/sample-factory and does not speed up simulation, but it allows you to interleave simulations from two sets of environments. It’s a good trick, but it is superseded by the final optimization, which is faster and simpler.
Run a pool of environments and sample from the first ones to finish stepping. For example, if you want a batch of 24 observations, you might run 64 environments. At each step, the 24 for which you have computed actions are going to take a while to simulate, but you can still select the fastest 24 from the other 64-24=40 environments. This technique was introduced by https://github.com/sail-sg/envpool and is massively effective, but the original implementation is only for specific C/C++ environments. PufferLib’s implementation is in Python, so it is slower, but it works for arbitrary Python environments and includes native multiagent support.
Experiments
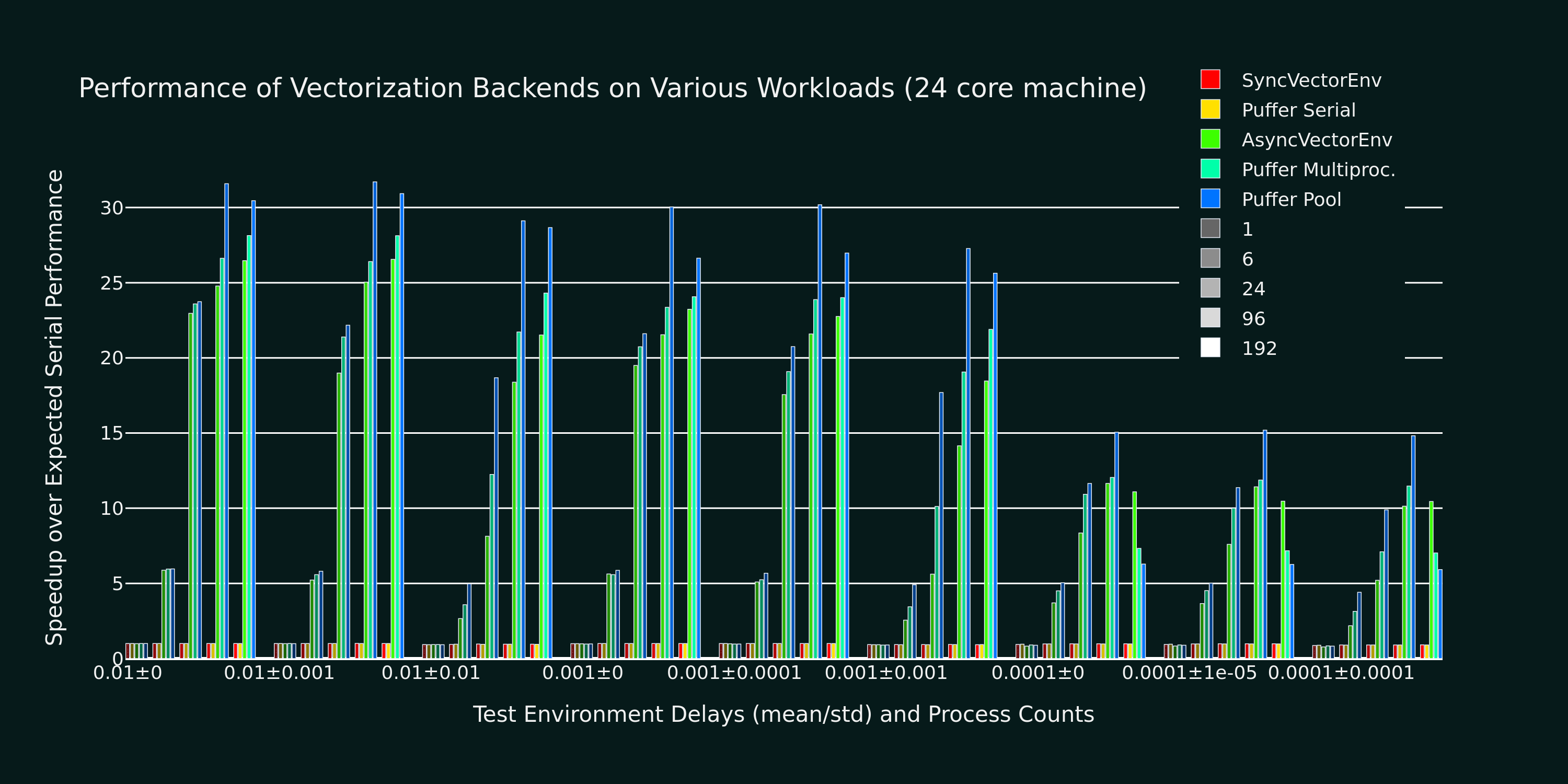
To evaluate the performance of different backends, I am using a 13900k (24 cores) on a max specced Maingear desktop running a minimal Debian 12 install. We test 9 different simulated environments: 1e-2 to 1-4 mean delay with 0-100% delay std. For each environment, we spawn 1, 6, 24, 96, and 192 processes for each backend tested (Gymnasium’s and Pufferlib’s serial and multiprocessing implementations + Pufferlib’s pool). We also have Ray implementations compatible with our pooling code, but that will be a separate post. Additionally, PufferLib implementations sweep over (1, 2, 4) environments per process and PufferLib pool will compute 24 observations at a time. We do not consider model latency, which can yield another 2x relative performance for pooling on specific workloads.
Envpool in PufferLib 0.5
9 groups of bars, each for one environment. 5 groups of bars per environment, each for a specific number of processes. The serial Gymasium/PufferLib experiments match in all cases. The best PufferLib settings are 10-20% faster than the best Gymasium settings for all workloads and can be up to 2x faster for environments with a high standard deviation in important cases (for instance, you may not want to run 192 copies of heavy environments). Again, this is before even considering the time saved by interleaving with the model forward pass.
All of the implementations start to dip ~10% at 1,000 steps/second and ~50% at 10,000 steps/second. To make absolutely sure that this overhead is unavoidable, I reimplemented the entire pool architecture as minimally as possible, without any of the environment wrapper or data transfer overhead:
As it turns out, Python’s multiprocessing caps around 10,000 steps per second per worker. There is still room for improvement by running more environments per process, but at this speed, small optimizations to the data processing code start to matter much more.
Technical Details and Gotchas
PufferLib’s vectorization library is extremely concise – around 800 lines for serial, multiprocessing, and ray backends with support for PufferLib’s Gymnasium and PettingZoo wrappers. Adding envpool only required changing around 100 lines of code but required a lot of performance testing:
Don’t use multiprocessing.Queue. There’s no fast way to poll which processes are done. Instead, use multiprocessing.Pipe and poll with selectors. I have not seen noticeable overhead from this in any of my tests.
Don’t use time.sleep(), as this will trigger context switching, or time.time(), as this will include time spent on other processes. Use time.process_time() if you want an equal slice per core or count to ~150M/second (time it on your machine) if you want a fixed amount of work.
The ray backend was extremely easy to implement thanks to ray.wait(). It is unfortunately too slow for most environments, but I wish standard multiprocessing used the Ray API, if not the architecture. The library itself has some cleanup issues that can cause crashes during heavy performance tests, which is why results are not included in this post.
There’s one other thing I want to mention for people looking at the code. I was doing some experimental procedural stuff testing different programming paradigms, so the actual class interfaces are in __init__. It’s pretty much equivalent to one subclass per backend.
PufferLib 0.4: Ready to Take on Bigger Fish
PufferLib 0.4: Ready to Take on Bigger Fish
PufferLib 0.4 is out now! Make your RL environments and libraries play nice with one-line wrappers, pain-free vectorization, and more.
One-line wrappers for your Gym and PettingZoo environments
Serial, Multiprocessing, and Ray vectorization backends
PufferTank, a container preloaded with PufferLib and common environments
More importantly, we have rewritten the entire core for simplicity and extensibility. While this is not a flashy new feature, you will notice significantly fewer rough edges working with PufferLib. For example, your Gym environments are no longer converted to PettingZoo environment internally, and your discrete action spaces are no longer returned as MultiDiscrete: WYSIWYG.
Emulation
Previously, PufferLib required you to wrap your environment class in a binding, which then provided creation and additional utilities. Now, you pass in a Gym/PettingZoo environment and get back a Gym/PettingZoo environment. All of the benefits described in our 0.2 blog post are included.
Previously, PufferLib’s vectorization expected a binding object. Now, you pass it an environment creation function (as above) or a Gym/PettingZoo PufferEnv, if you prefer to subclass directly. Compared to 0.2 PufferLib includes Serial and Multiprocessing backends, in addition to Ray.
import pufferlib.vectorization
import nmmo
vec = pufferlib.vectorization.Multiprocessing # Or Serial or Ray
envs = vec(nmmo_creator, num_workers=2, envs_per_worker=2)
# Synchronous API
obs = envs.reset()
# Async API
envs.async_reset()
obs, _, _, _ = envs.recv()
PufferTank
Many common RL environments are notoriously hard to set up and use. PufferTank provides containers with several such popular environments tested to work with PufferLib. These are preloaded onto base images so you can build the container over a coffee break.
Policies
Previously, PufferLib required you to subclass a PyTorch base class for your models. Now, you can use vanilla PyTorch policies. We still provide a base class as an option, which allows you to use another of our wrappers to handle recurrence for you. Pass your model to our wrappers and we will convert to framework-specific APIs for you.
Previously, PufferLib applied expensive runtime checks to all environments by default. These could be disabled by running with -O. This was inconvenient and easily forgotten. Now, these checks only run once at startup with negligible overhead. Thus far, we have observed no bugs with the new version that would have been caught by the previous checks.
Miscellaneous
We have added sane default installations, setup, and policies for several more environments. Check our home page for an updated list.
The new environment and policy changes means that PufferLib no longer breaks serialization. This is useful for saving environment and model states.
We have written an optimized flatten and unflatten function for handling observation and actions. This was previously a bottleneck for environments with complex spaces. Expect a separate post on this, since it was an interesting case study for Python extension options.
We have an experimental custom CleanRL derivative to correctly handle environments with variable numbers of agents, without training on padding. Doing this simply has been a longstanding challenge in RL. More on this once it is more stable.
Join us on Discord and tell us your pain points. We might just fix them.
PufferLib 0.2: Ready to Take on the Big Fish
PufferLib's goal is to make reinforcement learning on complex game environments as simple as it is on Atari. We released version 0.1 as a preliminary API with limited testing. Now, we're excited to announce version 0.2, which includes dozens of bug fixes, better testing, a streamlined API, and a working demo on CleanRL.
Problem Statement
To understand the need for PufferLib, let's consider the difference between Atari and one of the most complex game environments out there: Neural MMO. Atari is deterministic, fully observable, and single-agent, with relatively short time horizons and simple observation and action spaces. In contrast, Neural MMO is nondeterministic, only partially observable, and features large and variable agent populations, with longer time horizons and hierarchical observation and action spaces.
Most RL frameworks are designed with Atari in mind, resulting in limited support for multiple agents, complex observation and action spaces, and a bias towards small models with fewer than 10 million parameters. This makes it challenging for researchers to tackle more complex environments and leads many to focus exclusively on Atari and other simple environments.
CleanRL Demos
For our initial demo, we ran Neural MMO on CleanRL's single-file Proximal Policy Optimization (PPO) implementation designed for Atari by replacing only the vectorized environment creation code, without considering any of Neural MMO's complexities. For ease of experimentation, we have since wrapped CleanRL in a function and added additional logging. The latest version also includes double-buffering, an asynchronous environment simulation approach from the SampleFactory paper. To ensure the accuracy of our results, we maintain a public WandB profile with current baselines, including Atari results as a correctness check.
PufferLib Emulation
The key idea behind PufferLib is emulation, or wrapping a complex environment to appear simple, thereby “emulating” an Atari-like game from the perspective of the reinforcement learning framework. This approach handles environment complexity in a wrapper layer instead of natively by the reinforcement learning framework, allowing us to use simple reinforcement learning code with an internally complex environment.
We will use Neural MMO as a running example here. Neural MMO has hierarchical observation and action spaces, while most reinforcement learning frameworks expect fixed size vectors or tensors. PufferLib flattens observations and action spaces to conform to this expectation, without losing any structural information: both observations and actions are unflattened right before they are required. Reinforcement learning frameworks also expect vectorized environments to have a constant number of agents. PufferLib pads Neural MMO’s variable population to a fixed number of agents and also ensures they appear in the same sorted order. Finally, PufferLib also handles some subtleties in multiagent environment termination signals that are a common source of bugs. PufferLib works with single-agent environments, too!
Creating a PufferLib binding for a new environment is straightforward - simply provide the environment class and name in the pufferlib.emulation.Binding() function. Here's an example binding for Neural MMO:
The Binding class also accepts optional arguments to disable certain emulation features if they're not needed. Additional features include hooks for observation featurization and reward shaping, as well as the ability to suppress output and errors from the environment to avoid excessive logging.
PufferLib Vectorization
Most reinforcement learning libraries, including CleanRL, require vectorized environments that stack observation tensors across environments and split stacked actions across all environments. While a few options technically support multiagent environments, they are prone to difficult and finicky errors that are costly to debug. PufferLib takes a different approach by providing a wrapper with native support for multiagent environments. You can specify the number of CPU cores and the number of environments per core.
To use PufferLib's vectorization, create a VecEnvs object by passing in a binding and the number of workers and environments per worker:>
All other popular vectorization implementations are based on native multiprocessing. This works well for bug-free environments that adhere perfectly to the Gym API but quickly becomes cumbersome outside of this ideal setting. Multiprocessing does not scale natively beyond a single machine, eats stack traces from the environments, and does not allow direct access to remote environments outside of the multiprocessed functions. PufferLib's vectorization is backed by Ray, which scales natively to multiple machines, provides correct stack traces, and allows arbitrary access to individual remote environments. At the same time, it is shorter and simpler than any multiprocessed implementation. This vectorization approach makes it easy to reset environments with new maps, convey task specifications, or receive logging information that is not suitable for the infos field. We will cover this in a subsequent post with more detail.
The one major downside to using Ray as a backend is that it is not particularly fast. Ray itself caps at a few hundred to a few thousand remote calls per second. Currently, this is the price that has to be paid for simplicity and generality. Using larger batch sizes that require many simulated environments per core and employing async techniques like double-buffering can help mitigate this issue. Ultimately, as RL continues to scale up, the problem will solve itself as models become the bottleneck.
Next Steps
This release represents only a small part of what RL could be with better tooling. Here are some of our plans for future development:
Emulation features: We plan to add native support for team-based environments and better passthrough support for accessing any environment-specific features outside of Gym/PettingZoo. There is also room for performance optimization in this area.
Algorithmic features: We aim to provide PufferLib-compatible modules for commonly used methods in complex environments research, such as historical self-play, multiplayer skill-rating, and curriculum learning.
More integrations: In our initial release, we included both RLlib and CleanRL support. While we still provide an RLlib binding, we have focused on CleanRL as a faster testing mechanism in the early stages of development. However, PufferLib is designed to be easy to integrate with new learning libraries, and we plan to provide baselines for these as well.
Versioning Compatibility: The rapid progress of Gym/Gymnasium has created compatibility conflicts between specific environments, gym versions, and learning library dependencies. We are still on an old version of Gym from before all of this happened and are slowly increasing test coverage and compatibility with new versions.
Blog post by Joseph Suarez. Thank you to Ryan Sullivan for feedback and suggestions. Join our Discord if you are interested in contributing to PufferLib!